


I 메모리 장벽을 돌파하기 위한
메모리 계층 구조
메모리 장벽을 극복하기 위해 폰 노이만이 80년 전에 제안한 개념은 일종의 저수지, 즉, 버퍼(Buffer)다. 이중에서도 먼저 캐시(Cache)가 나온다. 단기 기억 정보들을 모아두는 작은 저수지 같은 개념인 캐시 메모리는 자주 참고해야 하는 데이터들을 언제든지 빠르게 읽고 다시 돌려보낼 수 있는 저장소 역할을 한다. 캐시는 버퍼 메모리 중에서도 동작 속도가 가장 빠른 SRAM이 주로 활용된다.
DRAM과 달리, SRAM은 플립플롭(flip-flop) 방식을 채용하기 때문에 커패시터(capacitor) 기반의 DRAM보다 정보를 읽기/쓰기 속도가 훨씬 빠르다(대략 200배 정도까지 속도 격차가 난다.). 대신 그만큼 더 많은 트랜지스터(4-6개)를 요구한다. DRAM은 1개의 트랜지스터만 쓰는 것과 비교하면 큰 차이가 있다.
따라서 SRAM이 DRAM에 비해 덩치도 더 크고, 구조도 복잡해지므로 공정 원가가 훨씬 높아져 시장가도 훨씬 더 비싸다(2025년 기준, GB당 DRAM 가격은 10달러 수준임에 반해 SRAM 가격은 5천 달러 수준이다.).
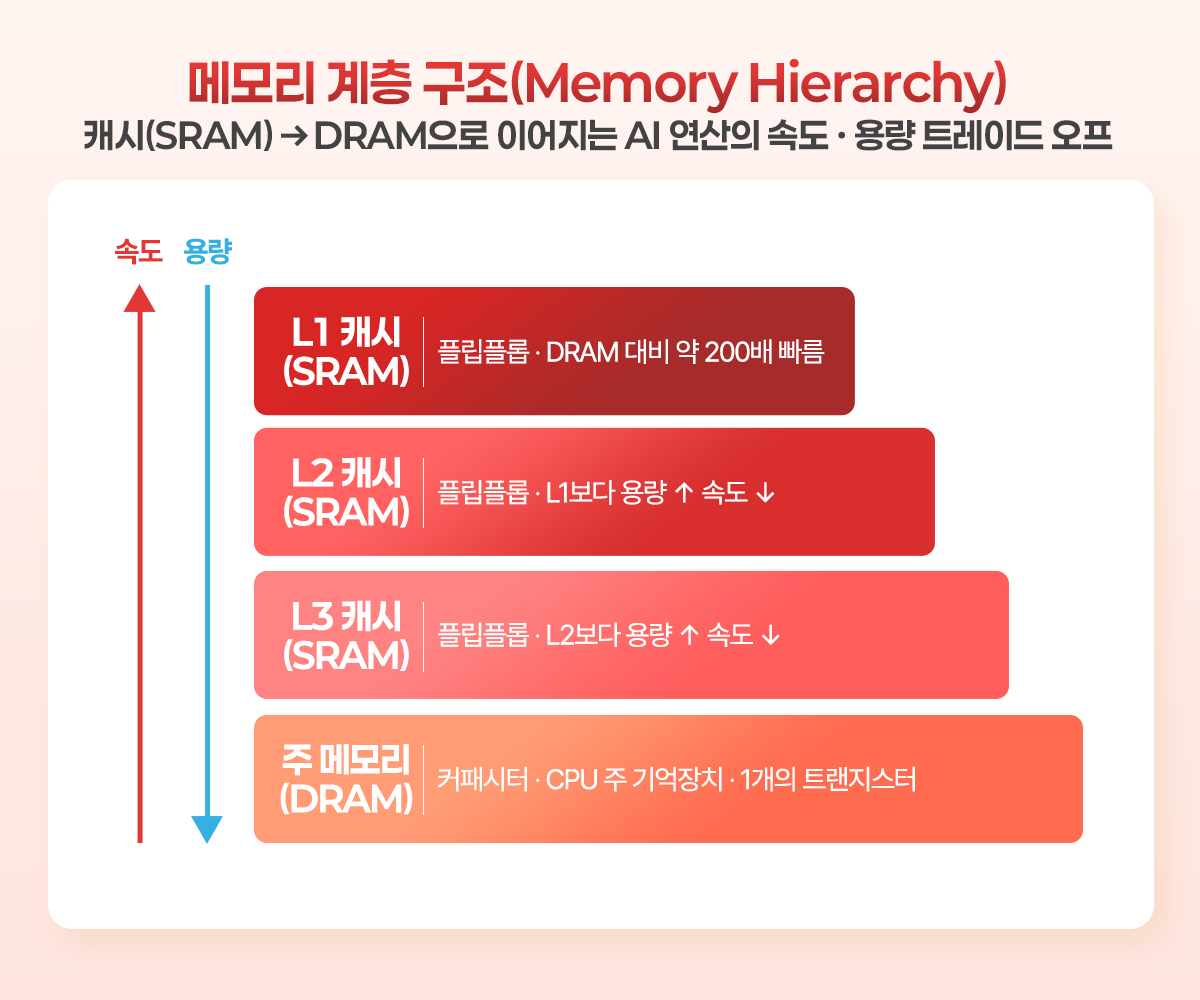
캐시 메모리 내부도 여러 계층으로 구분되는 방식으로 발전을 거듭해 왔는데, 이 계층은 데이터 접근 속도로 구분된다. 최근 방식은 가장 빠르고 용량이 적은 캐시 메모리가 L1(level 1), 그보다는 약간 느리고 용량이 더 큰 캐시 메모리가 L2(level 2), 그리고 다시 그보다는 더 느리고 용량도 더 큰 캐시 메모리가 L3(level 3)으로 구분되는 식이다. 사실 몇 층으로 구분되든지, 이러한 캐시 메모리의 목표는 메모리와 산술논리처리유닛(ALU) 간 속도 격차를 최소화하고, ALU가 참조하는 데이터를 최대한 빨리 공급하되, 그 정확도를 보장하는 것이다.
L1 캐시 메모리라고 해도 ALU의 기본 클럭 속도보다는 데이터 처리 속도가 떨어진다. 그래서 실제 CPU 코어의 클럭 속도는 결국 캐시 메모리의 대역폭에 맞춰 동기화된다. 속도가 빠른 SRAM 기반 캐시 메모리가 다층 구조화되어도, 결국 각 층이 가질 수 있는 용량에는 한계가 있으므로 CPU 주 기억장치로는 DRAM이 쓰인다. DRAM은 SRAM보다는 동작 속도가 느리지만 커패시터 충전만 주기적으로 해주면(이를 리프레시(refresh)라고 부른다.) 되므로 트랜지스터는 한 개만 있어도 된다. 따라서 단위 면적 당 집적도도 더 높아진다. 또한 양산 공정도 더 간단하게 만들 수 있으므로 수율 관리 측면에서도 더 유리하다.
I AI 특화형 고대역폭 메모리인 HBM
최근의 트랜스포머 기반 생성형 AI 모델, 특히 LLM에 기반한 AI 모델은 더 많은 신경망 파라미터가 더 높은 성능(지능)을 보여준다는 스케일링 법칙을 따라가고 있다. 그러나 더 커진 모델 사이즈는 더 큰 데이터를, 그리고 더 큰 데이터는 더 큰 메모리 장벽 문제를 야기한다. 예를 들어 메타(Meta)의 오픈소스 모델인 LLaMA 65B의 경우, FP16 형식 데이터 저장 시 토큰 하나를 만들기 위해서는 120-130GB 용량의 데이터를 한꺼번에 읽어 들여야 한다. 이 경우, 1초에 토큰 200개(세-네 문장 수준의 글)를 생성하려면 UHD 화질의 영화 100편을 1초 만에 다운로드할 수 있는 고속 메모리가 필요하다.
문제는 일반적인 DRAM으로는 이러한 속도는 달성이 불가능하다는 것이다. 저전력으로 작동하는 DRAM인 LPDDR을 사용할 경우 1초에 다운로드할 수 있는 UHD 화질의 영화는 0.5-1편에 불과한하다. 즉, LPDDR만으로는 1초에 토큰 200개 생성에 대해 100-200초, 즉, 3분 내외의 시간이 걸린다. 이렇게 되면 토큰 생성보다 데이터 읽기에 더 많은 시간이 소모되는 셈이다. 이러한 메모리 병목현상을 조금이라도 줄여보기 위해 2010년대 들어 등장한 대표적인 메모리 솔루션이 바로 HBM이다. 현재 HBM 글로벌 시장은 한국의 메모리 메이커들이 석권하고 있다.

HBM의 핵심 성능지표는 대역폭을 늘리는 것이다. 이는 비유하자면 고속도로의 차선의 개수를 대폭 증강하는 것에 비유할 수 있다. 문제는 그 고속도로를 지하에 만들어야 한다는 것이다. 이를 위해 작은 터널 역할을 하는 비아홀(via hole)의 개수를 최대한 늘리는 것이 가장 효과적이다. HBM3은 이러한 비아홀이 1,024개 있다. GPU core 주변에 적층 된 24GB 용량의 메모리 다이가 4개 배치되므로, 비아홀은 총 4×1,024 = 4,096개가 배치된다. 비아홀 한 개의 데이터 전송 속도는 0.8GB/s 이므로, 총 전송 속도는 3,276.8GB/s가 된다. 이렇게 만들면 무엇이 좋을까? 공정한 비교를 위해 HBM3의 동세대 DRAM에 해당하는 GDDR5의 속도를 생각해 보자. 코어(core) 주변에는 총 12개의 GDDR5 다이가 배치되고, 각 다이에는 32개의 핀(pin)이 있으므로, 총 384개의 데이터 입출력(i/o) 채널이 조성된다. 각 핀에서의 GDDR5 데이터 전송 속도는 2GB/s 이므로, 총 데이터 전송 속도는 768GB/s이 된다. 즉, 일반적인 DRAM의 데이터 전송 속도와 데이터 용량은 HBM3의 1/4 정도에 불과하다.
HBM3 다음 세대인 HBM3E는 채널 개수가 4,096개까지 확장되고, 각 다이 당 용량도 32GB까지 확장된다. 따라서 HBM3E는 GDDR5에 비해 용량은 6배 이상, 데이터 전송 속도는 16배 이상까지도 확장된다. 2026년 상반기부터 본격적으로 글로벌 GPU, NPU, TPU 제조사로 공급될 HBM4의 경우 12단 적층으로 확장되므로 용량은 10배 이상, 데이터 전송 속도는 24배 이상까지도 확장될 것으로 예상된다. 이 정도 속도가 되면 초당 토큰 생성을 300-500개까지도 감당할 수 있으므로, 메모리 장벽을 보다 효과적으로 완화할 수 있다.
I HBM의 제조 방식
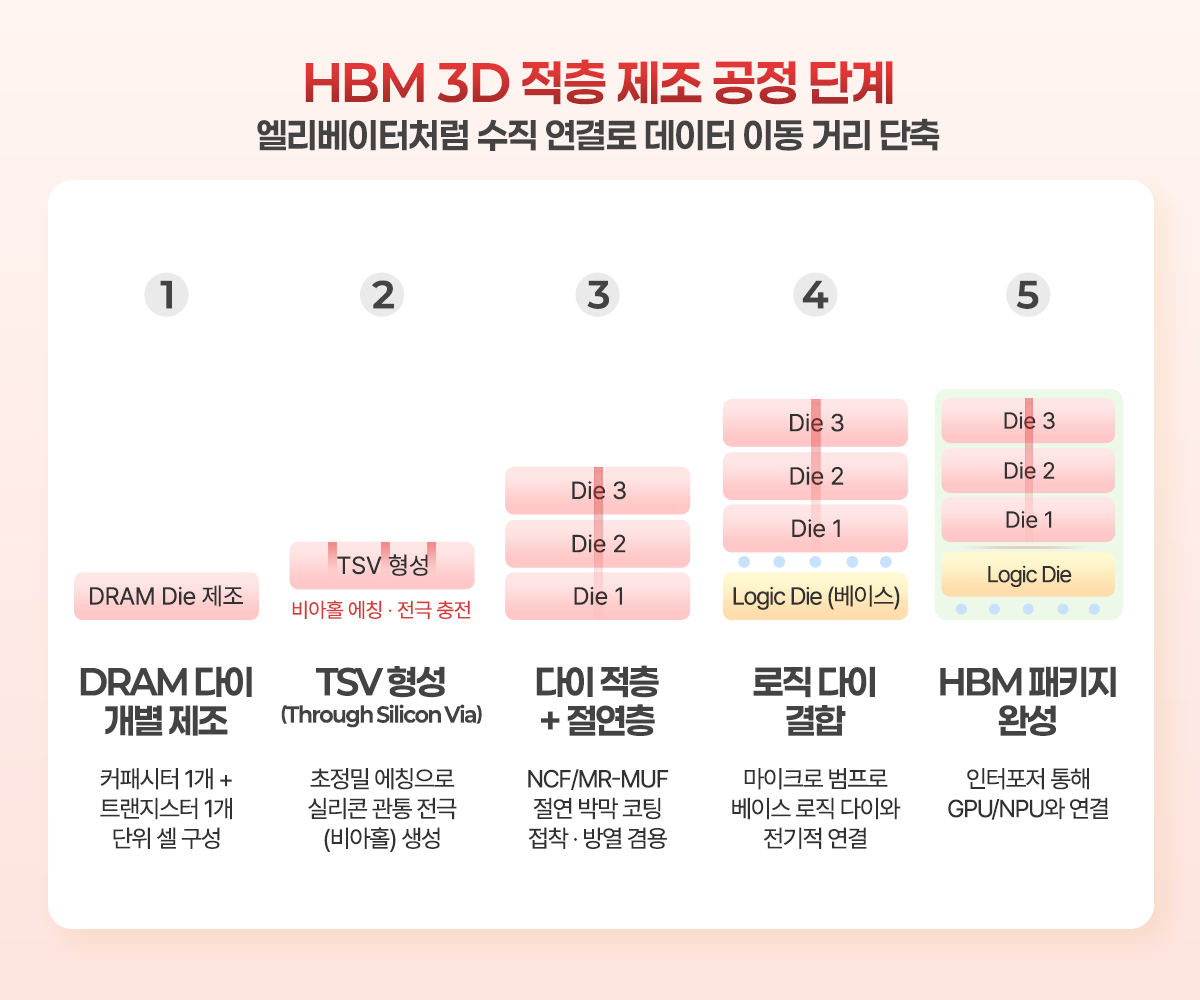
HBM은 DRAM 다이를 3차원으로 적층 제조한다. 이 방식은 3D 낸드플래시 같은 형태의 적층 공정과는 다르다. HBM의 핵심 목표는 적층된 다이들이 마치 하나의 메모리인 것처럼 작동하도록 동작을 동기화시키는 것이다. 이를 위해 적층한 메모리 셀을 하나로 이어주는 엘리베이터 같은 전극 채널이 필요하다. 이러한 전극은 비아홀이라는 긴 회랑 같은 구조를 채용하여 만들어지는데, 이를 위해서는 아주 얇고 긴 터널 구조를 만들어낼 수 있는 초정밀 에칭 기술, 즉, tsv(through silicon via)가 필요하다. 미세 엘리베이터는 일종의 데이터 고속도로 역할을 한다. 고속도로 차선이 많으면 더 많은 차들이 다닐 수 있듯, 더 많은 tsv가 있으면 한꺼번에 오갈 수 있는 데이터 규모, 즉, 데이터 대역폭도 늘어난다.
5세대 HBM인 HBM3E에서는 비아홀이 다이 당 2,048개 있다. 이것이 얼마나 많은 채널 개수인지 이해하기 위해서는 일반적인 GDDR의 핀 개수와 비교해 보면 된다. GDDR에서는 핀을 전극으로 이용하며 핀들은 다이 외부에 배치된다. GDDR의 핀은 다이의 엣지에 배치되므로 그 개수에는 제한이 있다. 예를 들어, GDDR5의 핀 개수는 32개인데, HBM3의 비아홀 개수가 1,024개임을 고려하면 32배 차이가 난다. 즉, 일반적인 GDDR5이 왕복 32차선 고속도로라면, HBM3는 왕복 1,024차선의 고속도로인 셈이다. DRAM을 적층 하여 이들을 수천 개의 tsv 채널로 이어주는 것만으로 HBM이 완성되지는 않는다. DRAM 셀 간에는 전도체로서 필요한 부분만 작은 금속 기둥의 연결 구조로 이어져 있어야 하고, 나머지 부분은 서로 전기적으로 절연되어야 한다. 이를 위해 셀 간에는 아주 얇은 절연층이 깔리는데, 이를 형성하기 위해 메모리 제조사들은 비전도성 박막(NCF(non-conductive film)) 같은 유기물 계열의 절연성 박막이나 MR-MUF(mass reflow molded underfill) 같은 방식으로 절연성 박막을 균일하게 코팅하는 공정에 집중한다. 이러한 박막은 적층 된 DRAM을 붙이는 접착제 역할도 하지만 데이터 입출력 과정에서 발생하는 열도 최대한 빠르게 방츨하는 역할도 겸해야 하므로 패키징 소재를 어떻게 만드는지는 앞으로 더 성능 요구 조건이 격해질 HBM 제조에 있어 이슈가 된다. 특히 고단 적층 방식, 두께를 얇게 만드는 조건에 대응하기 위해서는 이종 접합(hybrid bonding) 기술이 더 중요해질 것으로 예상된다.
I HBM을 대체할 수 있는 메모리

HBM이 타깃으로 삼는 성능은 데이터 대역폭을 늘려서 데이터 입출력 과정에서의 병목시간(레이턴시, latency)를 단축하는 것이다. 이를 위해 이론적으로는 HBM을 L3로 이용하는 구조를 생각할 수도 있다. 그러나 HBM만이 이 문제에 대한 유일한 솔루션은 아니다. DRAM을 개조하는 방법도 있다. 특히 DRAM 중에서도 RDIMM(registered dual in-line memory module)이나 MRDIMM(multiplexer-ranked DIMM) 같은 빠른 DRAM도 대안이 될 수도 있다. 이들은 필요할 경우 마치 캐시 메모리처럼 이용될 수도 있으면서, 또한 L3 캐시보다 훨씬 용량이 크다는 장점이 있다. 이를 위해 특정 회사의 메모리 데이터 전송 솔루션인 CXL(compute express link) 같은 CPU-메모리 인터커넥트 컨트롤러(inter-connect controller)가 가미되면 CPU와 메모리 간 데이터 주고받기 정합성 테스트에 소요되는 시간을 절약할 수 있으므로 에러 수정 시간도 단축시킬 수 있다.
GDDR이든, LPDDR이든, MRDIMM이든, CXL이든, 지금처럼 대용량 데이터의 빠른 처리, 특히 레이턴시 절감을 위해서는 일단 대역폭을 키우는 것은 여전히 중요하다. AI 반도체 개발 업체들 여기에 저전력, CPU와 메모리 사이의 물리적 거리 단축 등도 추구한다. 그렇지만 DRAM의 구조적 특성 상, 커패시터를 더 많이 욱여넣는 공정 동반은 피하기 어렵다. 즉, 커패시터 간 간격이 더 좁아져야 하는 것이다. 여기서 문제는 커패시터 간격이 작아질수록 신호 에러율이 높아지는 것이다. 예를 들어 이웃한 메모리 사이의 신호 간섭 에러 확률이 높아진다.
HBM을 대체할 수 있는 DRAM 혹은 그로부터 파생된 소자를 구성하는 아이디어로서 이른바 PIM(process-in-memory)도 있다. PIM은 원래 ALU 코어에서 담당하던 반복 계산 작업의 일부를 아예 메모리 단에서 하게 만드는 것이다. 이는 실제 컴퓨팅 하드웨어에서 사용하는 전력의 대다수(60-65%)가 CPU 코어와 메모리 셀 사이의 데이터 주고받기에 사용된다는 것에 착안한 전략이다. 이를 위해 PIM 용도로 LPDDR 같은 DRAM이 쓰일 수 있다. 특히 AI 학습/생성 데이터의 사이즈가 연간 10배 이상 급증하는 상황에서는 메모리 대역폭 한계와 레이턴시로 인해 계산 속도가 저하되고, 계산을 위한 전력 소모는 동시에 급증하는 상황을 막기 위해서라도 PIM은 더 진지하게 고려된다. LPDDR에는 PIM에 배정될 수 있는 부동소수점 처리 전문 모듈을 배치할 수 있는데, 이는 AI 연산에서 필수적으로 반복 실행되는 거대 행렬 곱셈 같은 연산에 특화된 구조로 형성될 수 있다. 혹은 부동소수점 단위를 경량화하여 행렬 연산 과정 중에 생성되는 데이터 임시 저장을 위한 메모리 공간을 절약할 수도 있다.
※ 본 콘텐츠는 외부 기고자의 개인적 견해를 바탕으로 작성되었으며, 당사의 공식 입장과는 무관합니다.

[LX세미콘 소식 바로가기]
LX세미콘 공식 뉴스룸
LX세미콘 공식 블로그
LX세미콘 공식 유튜브
LX세미콘 공식 페이스북
LX세미콘 공식 인스타그램


