


I 트랜스포머 기반 AI에 특화된 반도체 특성
트랜스포머가 기반의 AI 모델이 주력으로 활용되는 이상, 모델에서 필요로 하는 거대한 행렬 연산을 효과적으로 감당할 수 있는 기술은 계속 병목이 된다. 이를 쉽게 이해하기 위해 AI 알고리즘이 데이터 처리에 의해 속도가 결정되는지, 아니면 메모리 접근에 의해 속도가 결정되는지를 나눌 필요가 있다.

트랜스포머가 기반의 AI 모델이 주력으로 활용되는 이상, 모델에서 필요로 하는 거대한 행렬 연산을 효과적으로 감당할 수 있는 기술은 계속 병목이 된다. 이를 쉽게 이해하기 위해 AI 알고리즘이 데이터 처리에 의해 속도가 결정되는지, 아니면 메모리 접근에 의해 속도가 결정되는지를 나눌 필요가 있다.
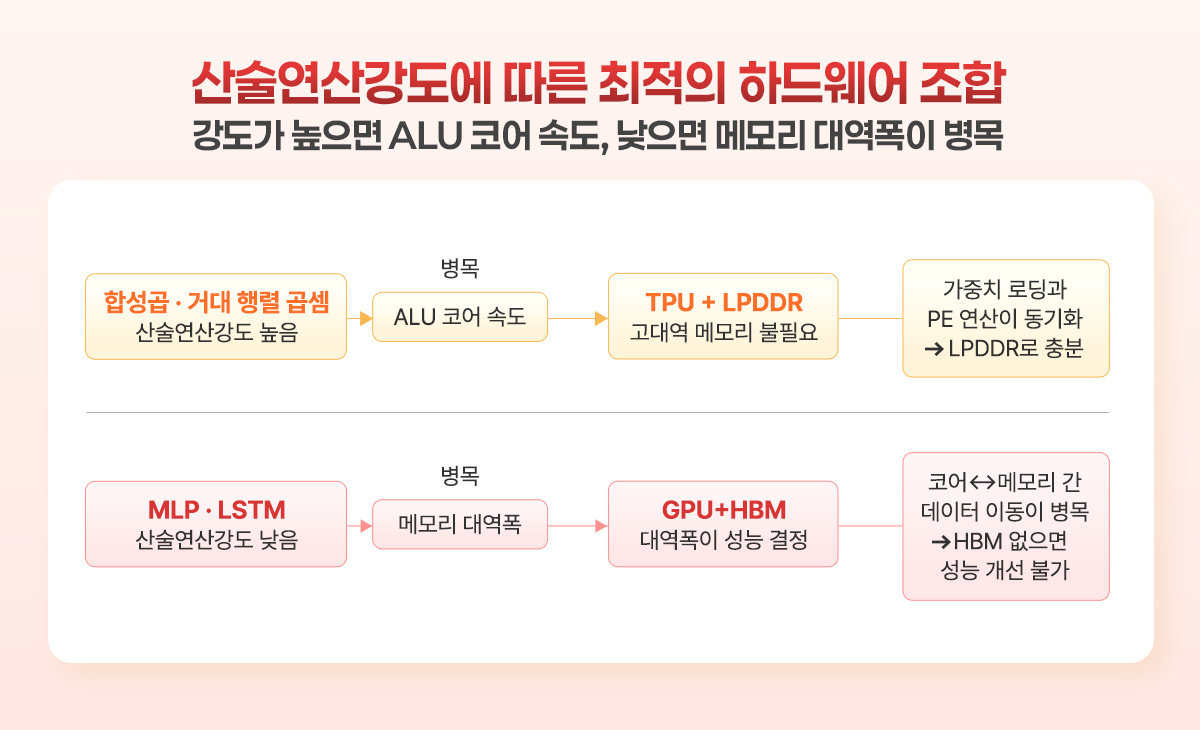
전자는 컴퓨트바운드(compute bound), 후자는 메모리바운드(memory bound)라고 부른다. 전자에 해당하는 AI 알고리즘들은 상대적으로 가벼운 메모리 대역폭 하에서 단위 시간 당 연산을 몇 번 할 수 있는지에 초점이 맞춰져 있고, 산술연산강도(arithmetic intensity)가 높다. 산술연산강도가 높다는 뜻은 그만큼 데이터 프로세싱 코어의 성능에 의해 전체적인 계산 성능이 좌우된다는 뜻이다. 산술연산강도가 높은 알고리듬에서 M-by-M 크기의 정사각 행렬 두 개의 곱셈을 할 경우, 산술연산강도는 이론적으로는 (2M-1)/3으로 계산된다. 따라서 행렬의 크기가 커질수록 연산의 성능은 메모리가 아닌 ALU 성능이 중요해진다.
높은 산술연산강도를 갖는 알고리듬 특화 반도체는 이른바 시스톨릭 아키텍처(Systolic architecture)라는 부르는 구조를 갖는다. 메모리에서 불러온 데이터들은 프로세싱 엘리먼트(Processing elements (PE))라고 부르는 연산 블록들의 연결망으로 입력된다. PE들은 마치 바둑판처럼 격자로 연결된 데이터 파이프라인 그물망을 갖는데, 이들의 특징은 각 블록에서는 정해진 단순한 곱셈, 덧셈 계산만 하고, 그 결과를 바로 이웃한 블록에 전달해 준다는 것이다. 이 과정에서 각 블록에서 계산한 데이터들이 각 블록에 저장되는 일은 없다. 농구에서 패스를 할 때 볼을 손에 잡아 들고 있지 않고, 그냥 툭 쳐서 다른 선수에게 빠르게 패스하는 방식을 생각하면 된다. 이렇게 하는 이유는 데이터 연산 과정에서 최대한 시간을 절약하기 위해서다. 절약되는 시간은 물론 각 블록에서 생성된 임시 데이터들의 저장과 로딩에 걸리는 시간이다. 그러면 이런 생각이 들 수 있을 것이다. 거대한 행렬 계산을 할 때 행렬을 여러 덩어리(블록)로 쪼개서 각 블록에 할당하여 계산한 후, 이들을 모으기 위해서는 그 중간 계산 결과는 어딘가에는 저장되어 있어야 하는 것 아닌가 하는 것이 바로 그렇다. PE들의 그물망 가장 바깥에는 그렇게 해서 모인 계산 결과들이 차곡차곡 쌓여 전달되는 메모리 셀이 배치된다. 이러한 방식으로 최적화된 연산 코어가 바로 NPU(neural processing unit)다. 대표 사례로서 구글의 TPU(tensor processing unit)가 있다. TPU는 연산 하드웨어 구조가 행렬을 닮도록 설계되어 구조도 상대적으로 간단하다.
I TPU 기반 AI 코어용 메모리
TPU 기능의 절대다수는 행렬 곱셈 연산에 필요한 PE 연결망과 연결망의 최외곽에 배치되는 I/O 용 메모리 셀이다. 애초에 연결망의 사이즈와 메모리 셀의 개수가 일치하게 설계되었고, 각 PE 노드 간의 데이터 이동 속도는 메모리 셀과의 통신 속도와 동기화되었으므로, 레이턴시 문제도 최소화될 수 있다.
문제는 이러한 시스톨릭 방식의 TPU는 다루게 되는 행렬 데이터의 차원이 연결망 차원의 약수 혹은 배수가 아니거나, 행렬 내부 성분이 드문드문 분포하거나(즉, 행렬의 구성 성분이 대부분 0인 경우), 정사각행렬이 아니거나 한 경우에는 연산 효율이 떨어진다는 것이다. 왜냐하면 행렬을 작은 블록으로 나누고 재배치하는 것 자체에도 시간이 소모되기 때문이다.
TPU의 원리상, 결국 산술연산강도가 높은 AI 알고리즘에서 다루는 행렬 연산이 주로 곱하기 연산에 시간이 많이 걸리는 상황이라면, 이에 필요한 메모리는 그다지 고대역일 필요가 없다. 메모리에서 잡아먹는 시간은 주 메모리(즉, off-chip DRAM) 저장된 가중치 벡터/행렬을 TPU core 옆에 있는 on-chip memory (즉, PE 연결망의 외곽에 연결된 input memory 셀)로 불러오는 것, 그리고 PE 연결망에서 계산된 결과를 전달받는 on-chip memory(즉, PE 연결망의 외곽에 연결된 output memory 셀)에서 다시 주 메모리로 전달하는 정도가 대다수다. 메모리 대역폭을 최대한 활용하기 위해, 시스톨릭 구조에서는 한 배치 당 가중치 벡터 로딩과 PE 연결망 연산이 동기화되도록 구조를 짠다.
그렇다면 적어도 거대 행렬 연산, 그것도 곱하기가 주종을 이루는 상관성, 합성곱 등에 대해서는 높은 산술연산강도를 갖는 연산 알고리듬인 합성곱 신경망을 위해 TPU+LPDDR 조합이 GPU+HBM 조합보다 유리할 수도 있을 것이다. 다른 알고리듬, 예를 들어 MLP(multi-layer perceptron)이나 LSTM는 상대적으로 산술연산강도가 낮고, 따라서 메모리에 병목이 걸리는 메모리바운드(memory bound)가 되므로, TPU+DRAM 조합은 이번에는 불리해진다. 이 조합은 메모리 대역폭을 고려한 구조가 아니기 때문이다. 즉, 이 조합에서는 HBM같이 대역폭이 대폭 강화된 메모리를 쓴다고 해서 연산 성능의 개선을 기대하기는 어려울 것이다.
I AI 전용 차세대 메모리에 요구되는 조건
AI 용 메모리 특징을 고려하여 두 가지 상황을 생각해 보자. 예를 들어 MLP는 주로 분류나 회귀 예측 등의 계산, 즉, 규칙성이 없거나, 패턴이 뚜렷하지 않은 이미지, 텍스트, 시계열 데이터 처리에 유리하다. 반면 합성곱신경망(CNN)은 데이터 상관성이 있을 때 더 유리하다. 예를 들어 위치적 상관성이 있는 이미지 데이터 처리에서는 CNN에서 다루는 합성곱(convolution) 연산에서 이미 많은 중간 단계 정보를 뽑아낼 수 있다. 합성곱을 담당하는 행렬이 일종의 필터가 되기 때문이다. 그래서 텍스트 분류나 영상 인식에서 자주 활용된다.
LLM 알고리즘이 메모리바운드 AI 알고리즘인 환류신경망(RNN), LSTM 등에 기반할 경우, 결국 앞으로도 메모리 대역폭이라는 병목 현상을 해결하기 위해서 더 큰 대역폭을 추구하는 방향으로 컴퓨팅 하드웨어가 추구될 것이므로, 현재 이 방향에서 선두를 달리고 있는 HBM이 계속 주력이 될 것이다. 반면, 컴퓨트바운드 AI 알고리즘인 CNN 등은 짧은 텍스트 인식과 분류, 사이즈가 정해진 영상 인식 및 합성에 특화될 것이므로, 이러한 엣지AI 전용 연산에서는 하드웨어 레벨에서 미리 신경망을 PE 블록 단위로 빌트인 한 TPU(NPU)+LPDDR의 조합이 더 선호될 가능성이 높다.
그렇다면 HBM과 LPDDR 같은 범용 DRAM을 동시에 만드는 주요 메모리 메이커의 전략은 어떻게 바뀔까? HBM은 GPU core 맞춤형 캐시 메모리 역할을 하므로, GPU+HBM 조합은 AI 학습을 위한 레퍼런스로 작동한다. 따라서 앞으로도 당분간 파운데이션 모델 류를 포함한 대부분의 AI 학습/추론에서는 지배적인 하드웨어가 될 것이다. 메모리 메이커가 만약 자체적인 AI 반도체를 만든다면 그것은 엔비디아와 직접 경쟁하는 AI 서버용 GPU라기보다는 엣지 AI, 특히 모바일 환경에서 작동하는 경량 AI 칩이 될 것이다. 특히 컴퓨트바운드에 대해서는 CXL이 뒷받침이 되는 LPDDR, MRDIMM, LDIMM 등으로 여러 종류의 맞춤형 DRAM을 세분화하여 각 코어 업체들, 팹리스 회사들과 협력하거나, 아예 자체적으로 NPU 코어를 만들어서 대응할 수도 있다.
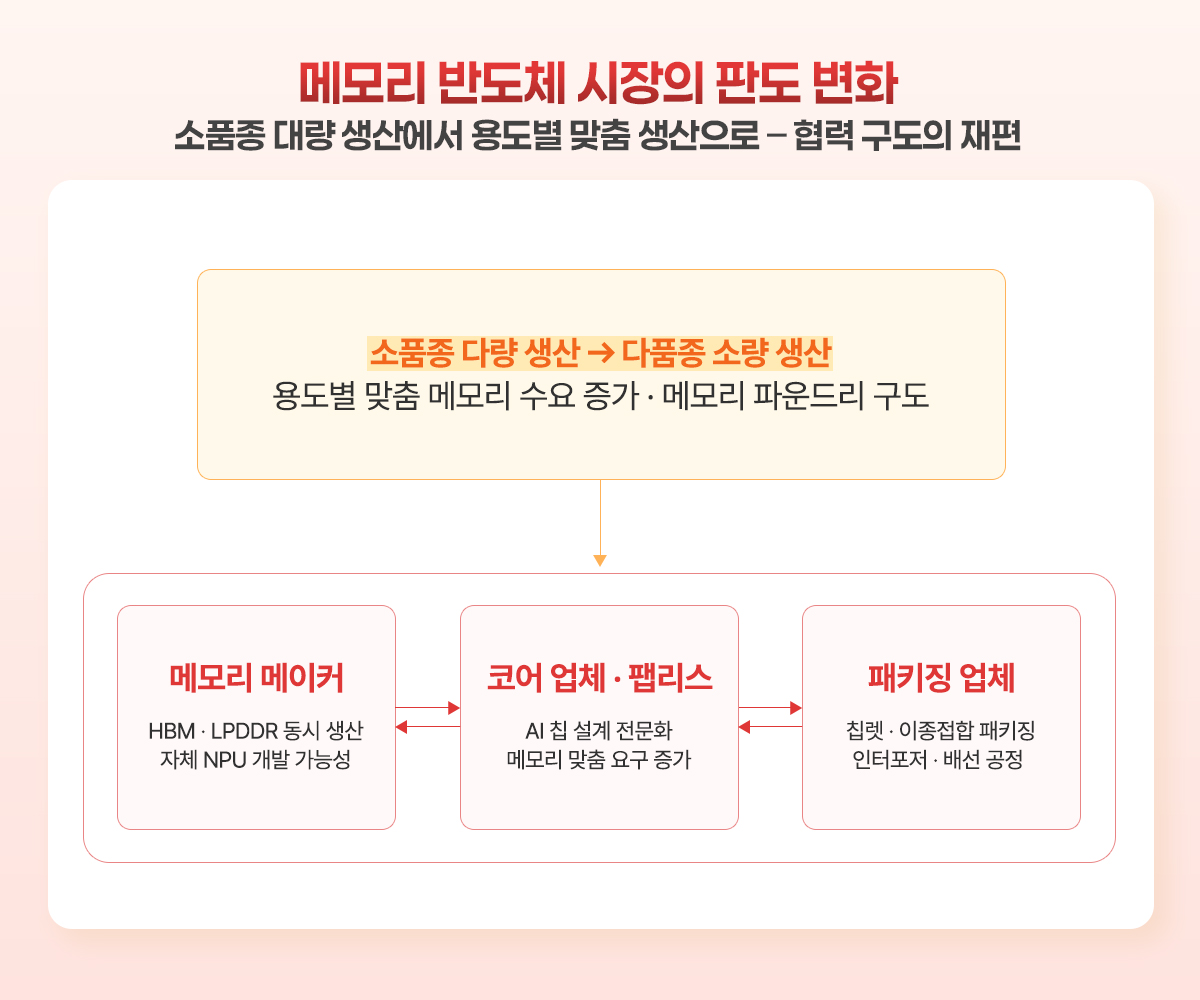
지금까지의 DRAM을 그저 범용 반도체, 소품종 다량생산, 치킨게임의 주무대, 한국의 독점 시장 정도로 파악하고 있었다면, 이제는 이러한 시각이 바뀌어야 하는 시점이다. AI로 촉발되는 시장의 변화가 컴퓨팅 하드웨어 전체를 재편하는 방향으로 흐르고 있기 때문이다.
특히 AI 반도체에서 미국의 집중 견제를 받는 중국의 메모리 반도체 업체들은 자체적인 기술 시도를 많이 할 텐데, 중국의 특정 DRAM 업체는 지속적인 DRAM 기술력을 축적하여 결국 HBM3 양산을 2025년 하반기 들어 시도하고 있으며, 또 다른 중국의 낸드플래시 메모리 반도체 메이커는 3D 낸드플래시 일변도의 전략에서 이제 온디바이스 AI용 메모리 시장으로 진입하고 있다. AI 반도체 용 메모리 시장이 다변화되면서 시장은 다품종 소량 생산, 메모리 파운드리 구도로 바뀌게 될 것이다. 컨트롤러, 인터포져, 배선 공정, 이종접합 패키징, 메모리-코어 칩렛 패키징 기술 등을 갖춘 업체들이 다양한 경쟁과 협력 구도를 이루며 시장의 동역학을 복잡하게 만들 것으로 예상된다.
I AI 반도체 시장 경쟁의 구도

앞으로도 AI 시장은 꾸준히 성장할 것이다. 이는 IT 산업뿐만 아니라, 기계, 조선, 로봇, 화학, 에너지, 전력, 통신, 건설, 농업, 그리고 바이오와 생명과학 분야에 이르기까지 실로 다양한 산업 영역 전반에 걸쳐 산업의 여러 층위를 혁신하는 새로운 엔진이 될 것이다.
그 한가운데에는 각 기능에 특화된 AI 알고리즘들이 있겠지만, 그것을 실현하는 것은 각 분야에 특화된 도메인 지식을 학습하기에 최적화된, 그리고 학습 과정에서 반드시 동반되어야 할 대용량 행렬 계산에 특화된 학습-추론-예측-인식에 특화된 AI 전용 칩이 될 것이다. 이에 대해 이미 지난 10년 간 사실상 독점적인 위상을 차지하여 이미 시장의 대세가 된 현재 업계를 리딩하는 특정 업체의 지배력은 당분간 무너지지 않을 것이다. 현재로서는 AI 반도체 수요에 비해, 공급이 부족한 공급자 위주의 시장이지만, 이 비대칭 구조의 틈을 노리면서 다양한 AI 칩 제조 전문 기업들이 특정한 응용 분야를 노리면서 시장에 진출할 것이다. 현재 업계를 리딩하는 특정 업체가 시작한 반도체 전쟁은 AI 산업 전체는 물론, 국가 간의 패권 경쟁의 한가운데에 위치하게 될 것이고, AI 칩에서 촉발될 다양한 제조업 경쟁의 핵심 축 역시 AI 반도체의 설계, 제조, 그리고 확보로 결정될 것이다.
특히 한 회사가 AI 반도체 관련 전체 시장을 다 지배하기는 점점 어려워질 것임은 확실하므로, 업체들이 어떻게 합종연횡과 차세대 기술 표준 주도, 그리고 기술 장기 발전 방향의 로드맵을 제시하는 과정에서 리더십을 확보할 수 있을 것인지 그 전략에 관심을 둘 필요가 있다.
※ 본 콘텐츠는 외부 기고자의 개인적 견해를 바탕으로 작성되었으며, 당사의 공식 입장과는 무관합니다.

[LX세미콘 소식 바로가기]
LX세미콘 공식 뉴스룸
LX세미콘 공식 블로그
LX세미콘 공식 유튜브
LX세미콘 공식 페이스북
LX세미콘 공식 인스타그램


