


2026년 3월, 미국 캘리포니아주 새너제이에서 열린 GPU 업계 최선두 업체의 연례 개발자 컨퍼런스인 GTC 2026은 단순한 신제품 발표 행사가 아니었다. 해당 회사의 최고경영자는 키노트 무대에서 ‘에이전틱 AI(agentic AI) 시대가 도래했다’고 선언하면서, 1조 달러에 달하는 자사의 수주 잔고를 공개하고 차세대 AI 인프라 플랫폼 전체와 로드맵도 한꺼번에 공개했다.
무대 위에서 펼쳐진 것은 단 하나의 칩의 쇼케이스가 아니었다. GPU, CPU, LPU, 스위치, 네트워킹 카드까지 7종의 반도체가 하나의 시스템으로 맞물려 돌아가는 이른바 ‘AI 팩토리’의 청사진이었다. 놀랍게도, 그 중심에는 처리 연산 코어가 아닌 메모리가 있었다. AI 반도체의 발전이 지금까지 얼마나 빠르게 연산 성능을 끌어올려 왔는지를 생각해 보면 이는 역설적인 풍경이다. 왜냐하면 연산 성능의 관건은 메모리가 아닌 코어에 달려 있다고 생각해 왔기 때문이다. 지난 10년간 AI의 발전은 주로 ‘학습(training)’이 이끌었다. 대형 언어 모델(LLM)을 비롯한 파운데이션 모델들은 막대한 양의 데이터를 반복적으로 학습하면서 성능을 키웠고, 그 과정에서 GPU 코어의 병렬 연산 성능은 가장 중요한 하드웨어 지표였다. 그러나 이제 전선은 모델 규모의 경쟁에서 ‘추론(inference)’의 효율, 더 정확히는 가격 대비 성능비, 전력 대비 성능비로 확연한 이동 양상을 보이고 있다. AI가 학습된 모델을 실제로 구동해서 결과를 만들어내는 추론 단계가 AI 산업에서 감축해야 할 주요 비용이자 동시에 핵심 수익원으로 부상하고 있기 때문이다. 학습이 공장을 짓는 일이라면, 추론은 그 공장을 하루 24시간 돌리는 일에 해당한다. 그리고 공장을 쉬지 않고 돌리는 데 있어 병목이 되는 것은 이제 코어가 아니라 바로 메모리 대역폭의 한계다.
I 추론 과정에서 메모리 병목 발생 원인
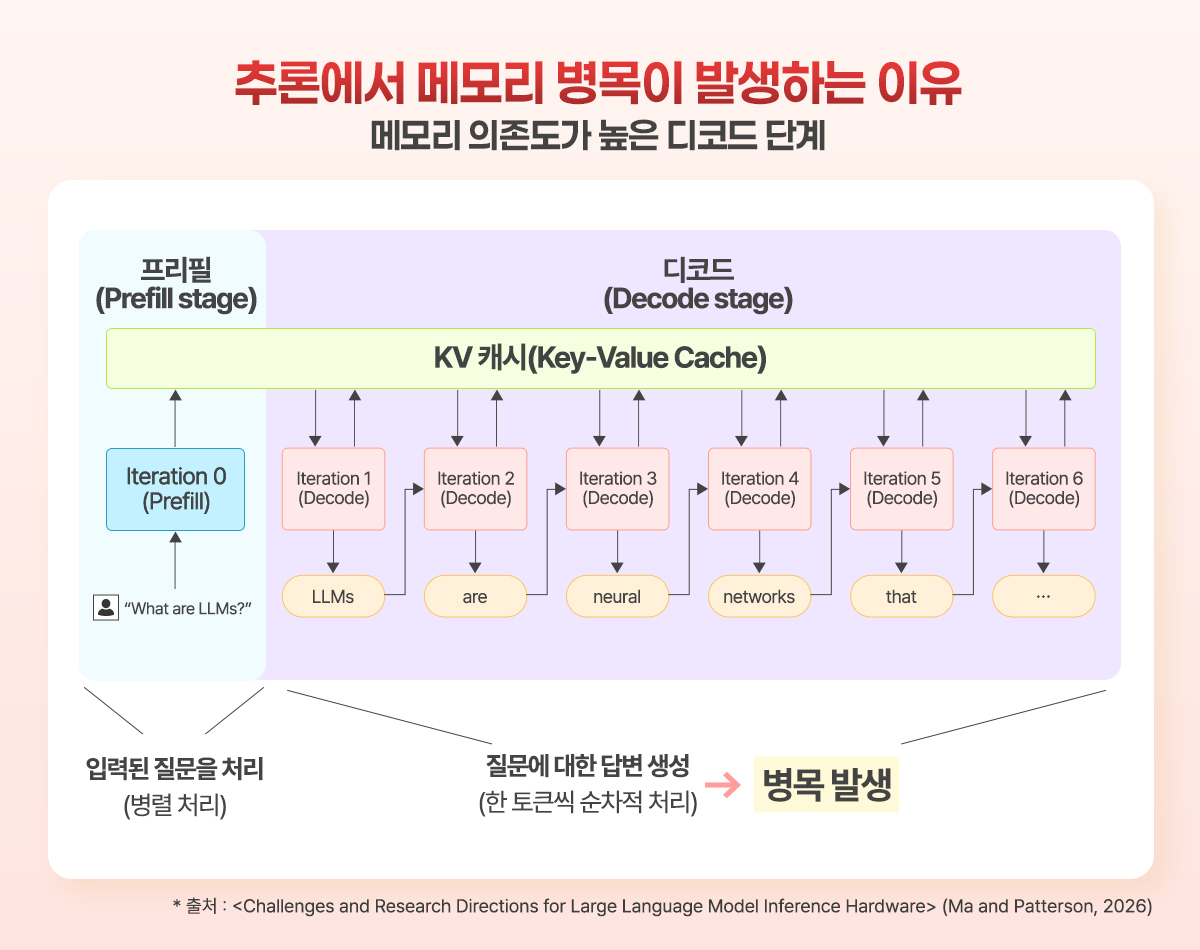
LLM이 텍스트를 생성하는 과정은 입력된 질문을 처리하는 ‘프리필(prefill)’ 단계와, 그 결과를 바탕으로 토큰 하나하나를 순차적으로 만들어내는 ‘디코드(decode)’ 단계로 나뉜다.
이 중 디코드 단계는 구조적으로 메모리에 의존할 수밖에 없다. 새로운 토큰 하나를 생성할 때마다 모델이 이전까지 처리한 모든 문맥 정보, 즉 KV 캐시(Key-Value Cache)를 메모리에서 읽어와야 하기 때문이다. 문제는 이 KV 캐시의 크기가 문맥 길이에 비례해 폭발적으로 증가한다는 데 있다. 4천 토큰짜리 대화에서는 현세대 HBM의 일부 용량만 차지하지만, 12만 8천 토큰짜리 문서에서는 HBM 용량 전체를 초과한다.
이는 단순히 용량의 문제가 아니다. 대역폭, 즉 단위 시간당 데이터를 얼마나 빠르게 읽고 쓸 수 있느냐의 문제이기도 하다. 아무리 용량이 크더라도 저장된 데이터를 꺼내 오는 속도가 느리다면 GPU 연산 코어는 데이터를 기다리며 엔진을 공회전시키게 된다. 이것이 이른바 ‘메모리 바운드(memory-bound)’ 현상이다. 오늘날 LLM 추론의 디코드 단계가 정확히 이 메모리 바운드 상황에 해당한다. GPU 연산 성능이 아무리 좋아도, 메모리에서 데이터를 충분히 빨리 공급하지 못하면 성능 개선이 제한되는 것이다.
앞선 3편에서 살펴보았던 HBM은 이 문제를 완화하기 위해 등장한 맞춤형 메모리였다. GTC 2026에서 공개된 차세대 GPU에는 6세대 HBM인 HBM4가 탑재되어 GPU 한 개당 288GB의 용량에 22 TB/s의 대역폭을 제공한다.
그러나 이 HBM도 근본적 한계를 지닌다.
첫째, 생산 비용과 수율 문제다. HBM은 열 장이 넘는 DRAM 다이를 정밀하게 쌓아 올리고, 그 사이를 수천 개의 미세 전극으로 연결해야 하므로 공정이 극도로 복잡하다.
둘째, 물리적 용량의 한계다. GPU 하나에 장착할 수 있는 HBM 스택 수에는 한계가 있으며, 문맥 길이가 수십만 토큰에 달하는 차세대 AI 모델 추론에서 이 한계는 뚜렷하게 드러난다. 바꿔 말하면, HBM이 AI 메모리의 왕좌를 차지하고 있음에도 추론 시대가 요구하는 수요를 HBM 하나만으로 충족시키기는 점점 어려워지고 있다는 뜻이다. 이 간극을 메우기 위한 새로운 시도들이 GTC 2026에서 동시다발적으로 등장했고, 메모리 업계는 이 변화에 주목하고 있다.
I 추론 전용 칩, SLAM 기반 LPU의 등장
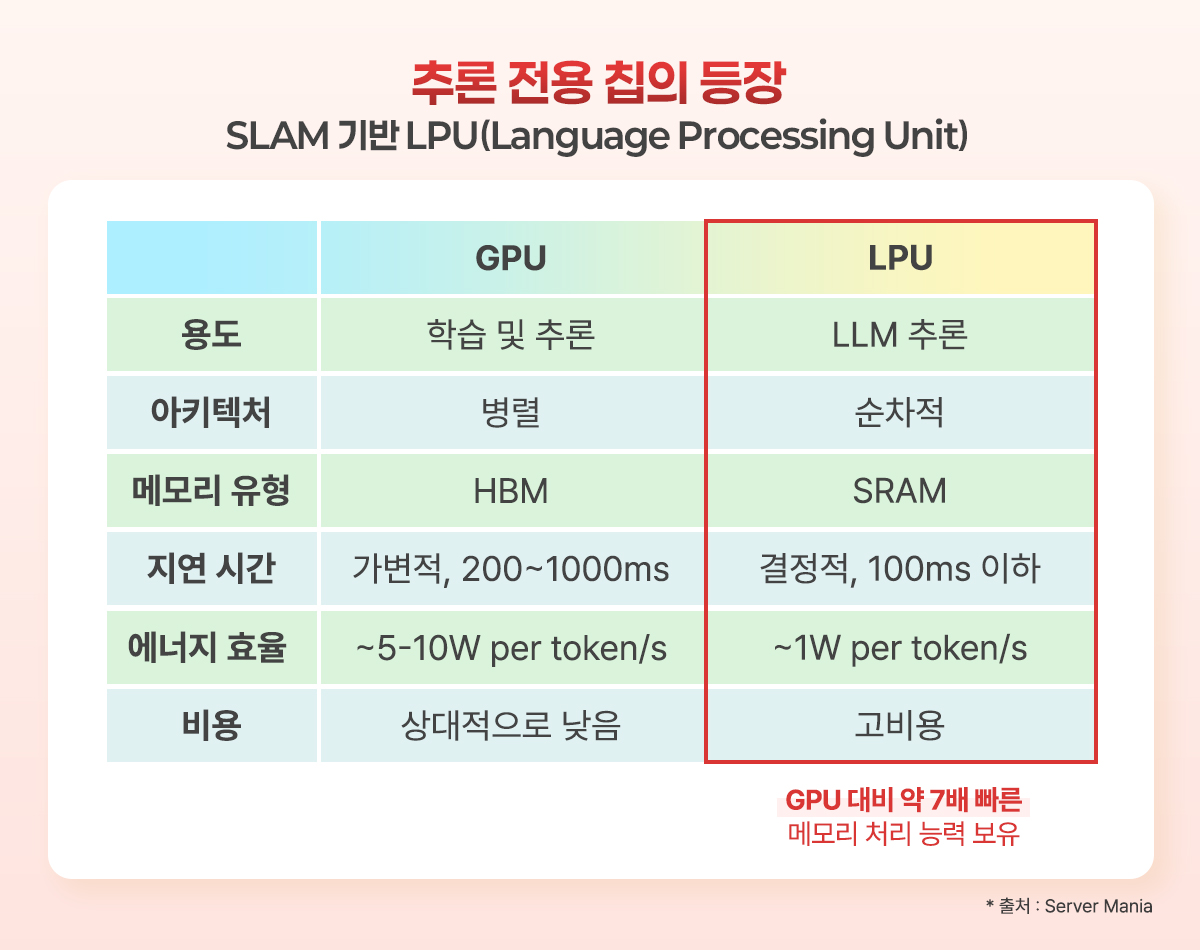
<그림 2> GPU와 LPU 비교
GTC 2026에서 가장 주목받은 발표 중 하나는 스타트업 G사의 기술을 기반으로 만든 새로운 코어 LPU(Language Processing Unit)였다. GPU가 HBM을 외부 메모리로 활용하는 구조를 택한 반면, LPU는 현존 가장 빠른 메모리인 SRAM을 칩 내부에 대규모로 탑재하는 방식을 택했다. SRAM은 DRAM에 비해 데이터를 읽고 쓰는 속도가 약 200배 빠르지만, 단위 면적당 집적 용량이 훨씬 적고 GB당 가격이 약 5,000달러(DRAM은 약 10달러)에 달한다.
이 때문에 업계에서는 대용량 SRAM을 추론 전용 칩에 탑재하는 것이 비현실적이라는 인식이 지배적이었으나, G사는 이 상식에 정면으로 도전했다. G사가 설계한 LPU 한 개에는 약 500MB 용량의 온-칩(on-chip) SRAM이 탑재되어 있으며, 이를 통해 총 150 TB/s의 메모리 대역폭을 달성한다. 이는 HBM4를 장착한 차세대 GPU 대역폭(22 TB/s)의 약 7배에 해당하는 속도다. 용량 면에서는 HBM에 비할 수 없이 작지만, LPU가 처리해야 하는 작업은 용량보다 속도가 훨씬 중요한 디코드 단계의 KV 캐시 처리라는 점에 주목할 필요가 있다. GTC 2026에서 제시된 수치에 따르면, 루빈 GPU와 G사의 LPX 랙(256개의 LPU를 담은 서버 랙)을 함께 운용할 경우 1조 파라미터급 모델의 추론 효율은 와트당 최대 35배 향상되며, AI 에이전트 간 통신 처리량은 초당 100토큰에서 1,500토큰 이상으로 15배 증가하는 것으로 추산된다.
I GPU와 LPU, 대체가 아닌 보완 관계로
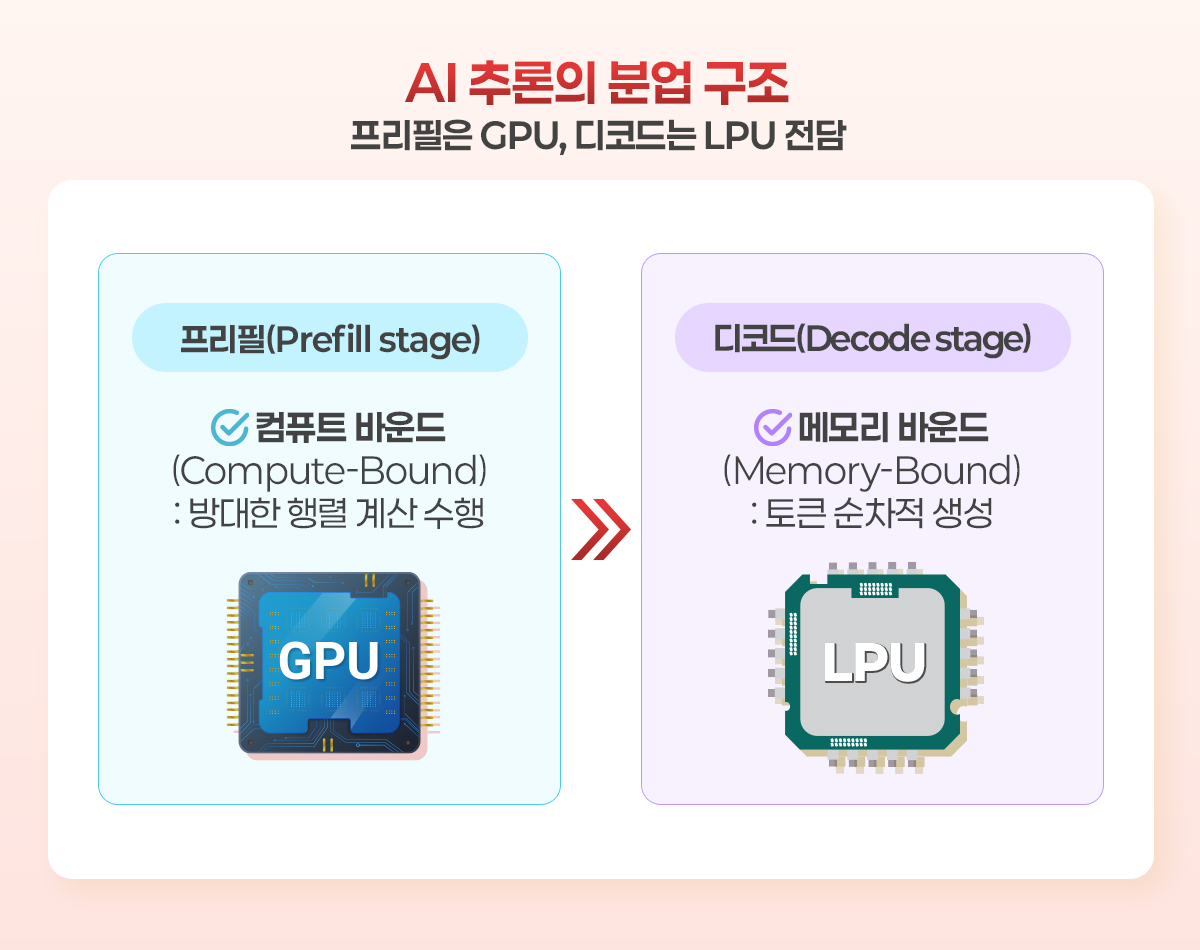
GTC 2026에서 발표된 새로운 메모리 전략은 HBM의 중요도가 감소할 것임을 의미하는 것은 아니다. GPU와 LPU를 경쟁 관계가 아닌 상호 보완 관계로 배치한다고 보는 것이 맞다. 마치 한 공장 안에서 생산 공정이 분업화되어 있듯이, AI 추론의 두 단계를 각자의 강점에 맞는 하드웨어가 전담하는 구조다.
입력 프롬프트를 한꺼번에 처리하는 프리필 단계는 수백억 개의 파라미터를 동시에 참조해 방대한 행렬 계산을 수행하는 ‘컴퓨트 바운드(compute-bound)’ 작업이므로 GPU의 대규모 병렬 처리 능력이 절대적으로 유리하다. 반면, 프리필이 끝난 후 토큰 하나하나를 순차적으로 생성하는 디코드 단계는 ‘메모리 바운드’ 작업이므로, 메모리 대역폭이 성능을 좌우한다. 바로 이 디코드 단계를 초고속 SRAM을 탑재한 LPU가 전담하는 것이다.
이러한 분업은 기술적 측면뿐만 아니라 비용적 측면에서도 의미가 있다. 전체 데이터센터 공간의 약 25%를 LPX-rack으로 채울 경우, 추론에서 가장 비용이 많이 드는 디코드 단계를 상대적으로 전력 효율이 높은 LPU로 처리함으로써 전체 시스템의 에너지 효율을 극적으로 향상시키는 전략이다. 실제로 제시된 데이터에 따르면 LPU와 GPU를 함께 운용했을 때의 추론 비용은 초당 500토큰, 100만 토큰당 45달러 수준으로 평가되었다.
I ICMS가 포함된 새로운 메모리 계층 구조

<그림 4> 메모리 수직 계열화 구조
GTC 2026에서 공개된 기술적 특징들을 종합하면, AI 반도체 시스템 자체, 특히 시스템의 메모리 구조가 근본적으로 재편되고 있음을 알 수 있다.
기존에는 칩 내부의 캐시(SRAM), GPU와 연결된 HBM, 시스템 DRAM, 그리고 대용량 저장장치(SSD)로 이어지는 비교적 단순한 피라미드 구조였다. 그런데 이제 이 구조에 새로운 계층들이 삽입되고 있다.
가장 빠른 층에는 LPU에 탑재된 온-칩 SRAM이 자리하며, 그 아래 HBM4가 GPU의 고속 메모리로 기능한다. 또 그 아래에는 CPU용 LPDDR5X 같은 DRAM이 놓이며, 실제로 베라 CPU 랙 한 개에는 400TB에 달하는 LPDDR 메모리가 탑재되어 강화학습과 에이전트 AI 워크로드를 지원한다. 여기에 ‘맥락(컨텍스트) 전용 메모리’ 계층이 새롭게 끼어든다. 이것이 바로 ICMS(Inter-Context Memory Storage)다. ICMS는 HBM이 수용할 수 없는 규모의 대용량 KV 캐시를 플래시 기반 저장장치에 보관했다가, 디코드 과정에서 필요할 때만 꺼내 쓰는 방식이다. 자주 참조되는 최근 문맥 정보는 HBM에 상주시키고, 상대적으로 덜 참조되는 오래된 문맥 정보는 ICMS로 내려보내는 핫/콜드(hot/cold) 분리 전략이다. 이 계층이 추가됨으로써(일부 전문가는 3.5층 메모리라고도 부른다) HBM 용량의 물리적 한계를 뛰어넘어 수십만 토큰에 달하는 초장문 컨텍스트 처리가 가능해진다.
이렇게 새롭게 정의되는 메모리 수직 계열화 구조는 결국, 속도가 가장 빠른 온-칩 SRAM이 최상위에서 실시간 디코드를 담당하고, HBM이 주력 고속 메모리로서 모델 파라미터와 활성 KV 캐시를 보관하며, ICMS가 장문 컨텍스트의 콜드 KV 캐시를 플래시 속도로 제공하고, 그 아래 SSD가 모델 가중치 오프로드와 장기 데이터를 담당하는 구조다. 이는 단순한 부품 개선이 아니라, AI 추론이라는 새로운 워크로드에 맞춰 메모리 생태계 전체를 재설계하는 작업이다.
I 메모리가 주도하는 AI 반도체 산업의 변화

<그림 5> 메모리 중심 경쟁이 가져올 변화
이러한 변화는 AI 반도체 산업의 경쟁 구도에 여러 중요한 함의를 내포한다.
첫째, 메모리 제조사의 전략적 위상이 달라진다. 지금까지 메모리 반도체는 AI 생태계에서 GPU를 보조하는 부품으로 인식되는 경향이 있었다. 그러나 메모리 대역폭과 계층 구조가 AI 추론 성능과 비용을 직접 결정하는 시대에서는 메모리 기술력이 AI 반도체 시스템 전체의 경쟁력을 좌우한다. HBM4의 양산 속도와 품질, 그리고 차세대 기술 로드맵이 AI 인프라 시장 전체의 방향을 결정할 수 있다.
둘째, ‘전용 메모리’의 시대가 본격화된다. 과거 DRAM은 범용 제품이었다. 같은 모듈이 서버에도, PC에도, 스마트폰에도 쓰였다. 그러나 AI 반도체의 발전은 용도에 따라 메모리 사양이 달라지는 방향으로 시장을 분화시키고 있다. HBM은 대규모 학습과 고성능 추론을 위한 전용 메모리이고, LPDDR5X는 AI 에이전트와 강화학습용 CPU 메모리로, 온-칩 SRAM은 초저지연 디코드 전용 메모리로, ICMS는 장문 컨텍스트 KV 캐시 전용으로 각각 기능한다. 메모리 시장이 소품종 대량 생산에서 다품종 맞춤형 생산으로 구조적 전환을 겪고 있는 것이다.
셋째, 아키텍처 혁신의 속도가 빨라진다. 비용이 수백 배 비싼 SRAM을 대규모로 탑재해 시스템 수준에서 압도적 성능 우위를 달성한 LPU의 사례는, 메모리와 컴퓨팅 코어 간의 경계가 허물어지며 앞으로 더 파격적인 하이브리드 아키텍처가 등장할 가능성을 시사한다. 2028년을 목표로 준비 중인 파인만(Feynman) 시리즈에서는 GPU 다이 자체를 3D로 적층하고, 맞춤형 HBM 변종을 탑재하는 방향이 예고되어 있다.
넷째, 에너지 효율이 새로운 경쟁 축으로 부상한다. 대형 데이터센터의 전력 소비와 그리드 과부하 문제가 사회적 이슈로 떠오르면서, 이제는 같은 AI 성능을 얼마나 적은 전력으로 달성하는지가 시스템 설계의 핵심 지표로 자리 잡고 있다. ‘와트당 토큰 처리량’이라는 새로운 지표가 AI 데이터센터의 지속가능성 주요 지표로 주목받는 것도 이 때문이다. GPU-LPU 하이브리드 시스템의 와트당 효율 35배 향상이라는 수치는, 에너지 효율이 이제 단순한 마케팅 수치가 아닌 데이터센터 투자 의사결정의 핵심 변수가 되었음을 반영한다. 이는 실제로 AI 모델을 파운데이션 모델에서 추론 전용으로, 추론 전용에서 도메인 산업 향 AX 전용으로 파인 튜닝하는 과정에서 수익률을 결정짓는 주요 변수가 될 가능성이 높다.
I 한국 메모리 산업 관점에서의 시사점

메모리 중심의 AI 반도체 방향이 구체화되는 추세는 한국 반도체 산업에도 중요한 전략적 과제를 제기한다. 한국은 DRAM이나 낸드플래시는 물론, HBM 같은 AI 특화 메모리 글로벌 시장에서 사실상 지배적 위치를 차지하고 있다. 그러나 메모리 계층 구조의 다변화와 추론 전용 메모리 시장의 확대, 온-디바이스 AI 전용 메모리 수요 증가는 단순히 HBM을 더 많이 만드는 것만으로 예전 같은 강고한 지배력 유지를 보장하지 못할 수도 있음을 시사한다.
특히 LPU에 탑재되는 대용량 온-칩 SRAM은 메모리 팹(fab)이 아닌 로직 팹에서 제조된다. 즉, SRAM 기반 추론 가속기 시장은 기존의 DRAM 양산 경쟁력만으로는 진입하기 어려운, 선단 공정 기반 시스템 반도체 제조 역량이 주요 변수가 되는 영역이다.
반면 ICMS와 같은 플래시 기반 컨텍스트 메모리는 낸드플래시 기술력과 시스템 레벨 설계 역량을 동시에 요구한다. 결국 AI 메모리 시장은 단순한 양산 규모 경쟁을 넘어, 다양한 유형의 메모리를 AI 시스템 아키텍처에 최적화하여 공급하는 ‘종합 메모리 솔루션’ 역량을 요구하는 방향으로 이동하고 있다.
더불어 급성장하는 중국 메모리 업체들의 동향도 주목해야 한다. 미국의 지속적인 기술 제재에도 불구하고 중국의 일부 DRAM 업체들은 자체적인 HBM3 양산을 시도하고 있으며, 특히 중국에서 빠르게 성장하는 AI 데이터센터와 자율주행차, 로봇 같은 피지컬 AI를 지원할 AI 반도체는 그에 비례하는 전용 메모리 공급선 다변화를 요구할 것이다. AI 메모리 시장이 다변화될수록, 이 경쟁에서 뒤처지지 않기 위해서는 기술 혁신과 시스템 통합 역량의 조기 확보가 더욱 중요해진다.
I 메모리 중심으로 재편되는 AI 반도체의 미래
GTC 2026은 AI 반도체가 단순한 고성능 연산 칩의 경쟁을 넘어, 메모리 설계와 메모리 계층 구조를 중심으로 한 시스템 수준의 경쟁으로 진화하고 있음을 분명히 보여주었다. 프리필과 디코드의 분리, GPU와 LPU의 역할 분담, HBM과 SRAM과 ICMS로 이어지는 메모리 계층 재편은 모두 같은 방향을 가리키고 있다. 에이전트 AI와 피지컬 AI의 쌍끌이로 AI 추론 성능 강화와 수요가 동시에 폭발적으로 증가하는 시대에, AI 작업 병목은 더 이상 연산 속도만이 아니라 메모리가 얼마나 빠르고 효율적으로 데이터를 공급할 수 있느냐에 달려 있다. ‘역사상 가장 큰 인프라 구축’이라고도 불리는 AI 팩토리의 심장부에는, 결국 어떤 메모리를, 어떻게, 얼마나 빠르게, 얼마나 정교하게 맞춤형으로 공급할 수 있느냐의 문제가 자리 잡고 있다. 메모리는 더 이상 GPU를 보조하는 부품이 아니다. 메모리가 AI 반도체 경쟁의 새로운 주인공으로 떠오르고 있다.
※ 본 콘텐츠는 외부 기고자의 개인적 견해를 바탕으로 작성되었으며, 당사의 공식 입장과는 무관합니다.

[LX세미콘 소식 바로가기]
LX세미콘 공식 뉴스룸
LX세미콘 공식 블로그
LX세미콘 공식 유튜브
LX세미콘 공식 페이스북
LX세미콘 공식 인스타그램


