


1, 2, 3편에서 허버트 사이먼의 ‘아키텍처 사고방식’부터 레베카 헨더슨의 ‘아키텍처 혁신’, 그리고 칼 울리히의 ‘제품 아키텍처’에 이르기까지, 아키텍처의 이론적 기반을 살펴보았다. 이제 이 ‘아키텍처’라는 창을 통해 현대 산업의 심장부인 반도체 산업을 본격적으로 들여다보고자 한다.
I 폰 노이만 방식으로 컴퓨터 구조의 변화

초창기 컴퓨터는 [도표 1]에서 보듯 ENIAC(1945)처럼 연산기 사이의 선 연결을 일일이 전환하는 ‘결선(배선) 논리(wired logic) 방식’을 사용했다. 이 방식은 프로그램을 변경할 때마다 케이블을 다시 연결해야 하는 불편함과 더불어, 처리 가능한 프로그램의 최대 규모가 하드웨어에 제약되는 ‘규모 제약 문제’ 및 시스템이 커질수록 접속 수가 방대해지는 ‘대규모 시스템의 접속 문제’라는 두 가지 근본적인 결점을 안고 있었다.
이 난제들은 폰 노이만(John von Neumann)과 잭 킬비(Jack Kilby)에 의해 해결되었다. 먼저 폰 노이만은 EDVAC(1949) 설계를 통해 데이터와 명령어를 메모리에 저장해두고 프로세서가 순차적으로 처리하는 ‘프로그램 내장 방식’을 고안해 ‘규모 제약 문제’를 해소했다. 뒤이어 잭 킬비가 1958년, 소자와 배선을 칩 하나에 일괄적으로 집적하는 ‘집적회로(IC)’를 발명함으로써 ‘대규모 시스템의 접속 문제’를 해결했다. 이 두 가지 거대한 혁신이 결합되면서 비로소 컴퓨터와 칩이 함께 진화할 수 있는 토대가 마련되었다.
⠀I 폰 노이만 구조 기반 컴퓨터의 계산 방식

<도표2>는 폰노이만 방식의 컴퓨터로, 계산 기능을 하는 CPU와 명령어와 데이터를 저장하고 있는 메모리가 서로 분리되어 있다. 기능과 구조가 1대 1로 대응되는 이 방식은 모듈형 설계로 이해할 수 있다. 이 그림을 통해 ‘폰 노이만 구조’의 동작 방식을 살펴보자.
예를 들어, 메모리의 3번지에 저장된 120과 4번지에 저장된 100을 더하는 프로그램이 있다고 하자. CPU는 제어 장치의 지시에 따라 먼저 메모리 1번지에 있는 ‘3번지와 4번지를 더하라’는 명령어를 읽어온다. 그런 다음, 이 명령에 따라 메모리 3번지와 4번지에서 실제 데이터인 ‘120’과 ‘100’을 가져와(그림의 ①), ALU(산술논리연산장치)에서 덧셈(②)을 수행한다. 그리고, 그 결과인 ‘220’은 일단 CPU 내부에 잠시 보관된다(③).
덧셈이 완료되면, CPU는 메모리의 다음 순서인 2번지로 이동해 ‘연산 결과를 저장하라’는 다음 명령어를 가져온다. <도표2>의 아래 그림은 바로 그 ‘저장’ 명령이 실행되는 모습이다. CPU의 제어장치가 ‘메모리 쓰기’ 신호(④)를 보내고, 아까 CPU 안에 임시로 보관했던 덧셈 결과 ‘220’을 메모리의 6번지 같은 빈 공간에 최종적으로 기록하는 것이다. 결국 이 그림은 메모리에 적힌 프로그램 순서(1번지, 2번지…)대로 명령을 하나씩 가져와 차례차례 처리하는 ‘순차 실행’ 과정을 보여주고 있다.
이와 같은 컴퓨터 아키텍처의 변화는 반도체 산업의 ‘성장 시나리오(Growth Scenario)’를 낳았다. 이 시나리오의 기본 원리는 디바이스의 ‘스케일링(scaling)’, 즉 미세화(miniaturization)였다. 칩의 집적도를 높이면 제조 비용을 낮추는 동시에 성능을 높일 수 있었기 때문이다. 이것이 바로 “프로세서의 집적도는 2년마다 2배, DRAM은 3년마다 4배씩 높아진다”라는 ‘무어의 법칙(Moore’s Law)’으로 알려진 경험칙이다. 이처럼 CPU와 메모리가 각자의 영역에서 ‘미세화’를 통한 고도화에 집중할 수 있게 되면서, 무어의 법칙은 50년간 산업을 이끄는 강력한 성장 엔진으로 작동해 왔다.
흥미로운 점은, 이 법칙을 만든 고든 무어(Gordon Moore) 자신도 언젠가 이 속도가 둔화될 것을 예견했다는 사실이다. 그는 1965년 4월 Electronics라는 잡지에서 반도체의 집적도가 ‘1년에 2배’씩 데이터 분량이 증가할 것이라 예측했다. 하지만 10년 뒤인 1975년 12월, 국제학회 IEDM에서 70년대 말부터는 그 속도가 ‘2년(24개월)에 2배’로 늦어질 것이라고 스스로 전망을 수정했다.
I 반도체 산업 성장의 세 가지 흐름
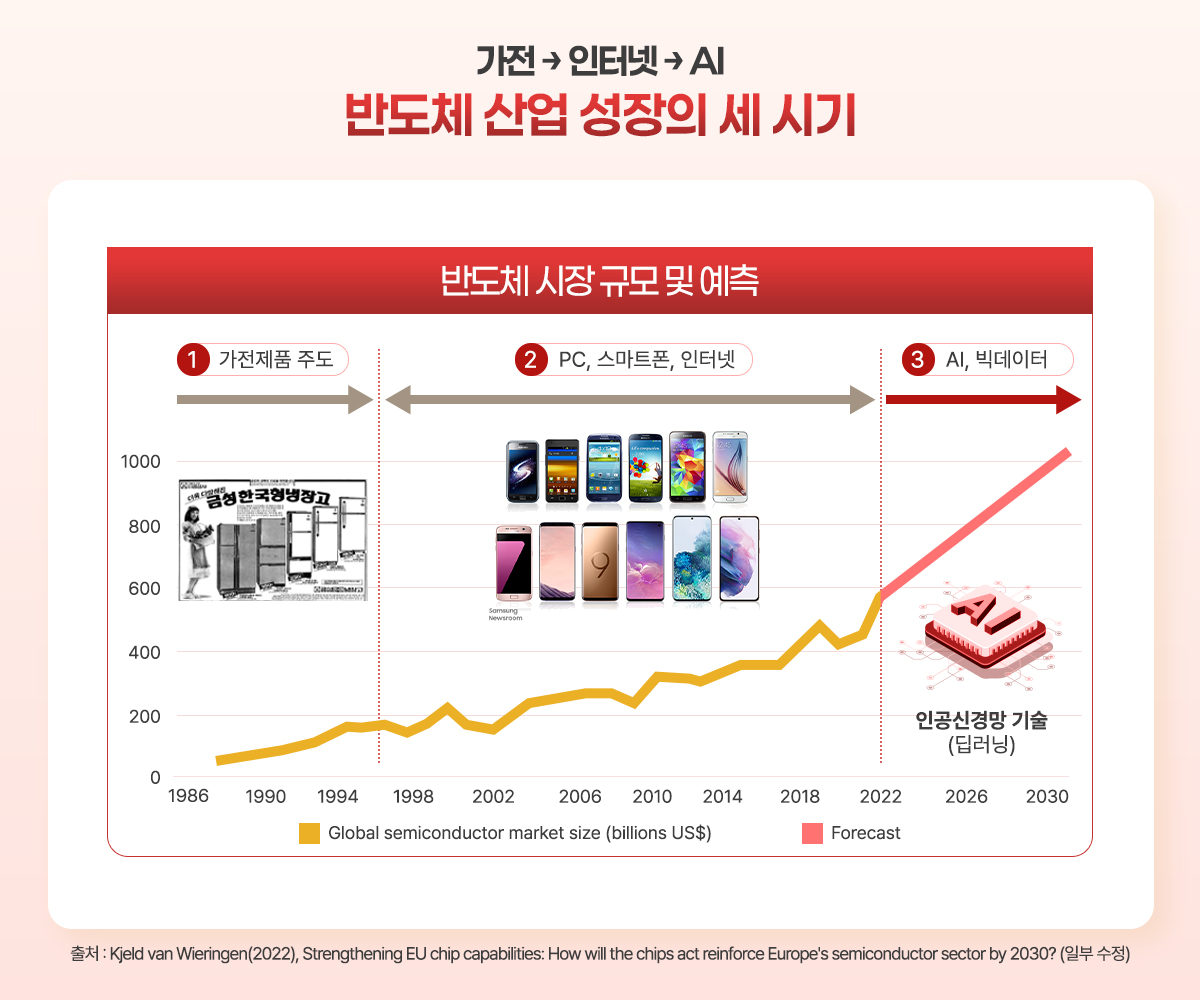
[도표 3]은 반도체 산업 시장 규모를 보여 주는 것으로, 반도체 시장의 성장을 크게 세 시기로 구분한다. 1차 시기(1986~1995)는 ‘가전제품이 주’가 되어 시장을 이끌었던 시기이다. 이후 1996년부터 2018년경까지는 2차 시기로, ‘PC, 스마트폰, 인터넷’이 시장의 성장을 견인했다. 그리고 2020년 이후, 시장은 ‘AI, 빅데이터’가 주도하는 3차 시기로 본격 진입하고 있다. [도표 4]는 이 3차 시기의 가파른 성장이 ‘인공신경망 기술(딥러닝)’에 의해 주도될 것임을 명확히 보여준다.
하지만 ‘AI, 빅데이터’가 주도하는 3차 시기는 과거 1, 2차 시기와는 근본적으로 다른, 거대한 도전을 안고 있다. 바로 ‘막대한 전력 소모’ 문제이다. 2016년 이세돌 9단과 알파고(AlphaGo)의 역사적인 바둑 경기는 이 문제를 극명하게 보여주었다. 당시 인간의 두뇌는 약 20와트(watt)의 전력만으로도 복잡한 사고를 수행했지만, 수많은 CPU와 GPU 서버로 구성된 인공지능 알파고는 무려 25만 와트(250,000W)가 넘는 전력을 사용했다. 이는 인간의 두뇌가 현재의 컴퓨터 시스템과 비교할 수 없을 정도로 에너지 효율이 높다는 것을 증명함과 동시에, 현대의 인공지능 기술이 얼마나 막대한 에너지를 필요로 하는지 보여주는 상징적인 사례가 되었다.
I 폰 노이만 구조의 에너지 낭비 문제

인공지능의 막대한 전력 소모 문제는 폰 노이만 구조의 근본적인 비효율성에서 상당 부분 기인한다. [도표 4]는 ‘컴퓨팅의 에너지 문제(Computing’s Energy Problem)’라는 제목의 2014년 ISSCC 논문에서 인용한 자료로, 이 문제를 명확히 보여준다. 이 도표는 CPU가 수행하는 단순 연산과 메모리 접근에 드는 에너지 비용을 비교한다. 가장 단순한 연산 중 하나인 ’32비트 덧셈(32b Add)’에 0.1 pJ(피코줄)의 에너지가 드는 반면, 메모리에서 ’32비트 데이터를 읽어오는(32b DRAM Read)’ 데는 640 pJ의 에너지가 소모된다. 즉, 데이터를 연산하는 데 드는 비용보다 데이터를 메모리에서 가져오는 데 드는 비용이 무려 6,400배나 더 크다는 것이다. 이는 AI와 같이 수많은 데이터를 메모리에서 CPU로 가져와야 하는 작업에서, 실제 연산(계산)이 아닌 데이터 이동(메모리 접근) 과정에 대부분의 에너지가 낭비되고 있음을 의미한다.
I 인공지능 시대의 과제 : 막대한 전력 소모

<도표5> LLM 모델 매체변수의 증가 추이
문제는 지금부터 반도체 사용의 주류가 될 인공지능은 극단적으로 많은 메모리를 사용한다는 점이다. 우리가 흔히 사용하는 챗GPT와 같은 LLM(Large Language Model)을 살펴보자. (도표 5)는 GPT 모델의 매개변수(Parameter)가 어떻게 기하급수적으로 증가했는지 보여준다. GPT-1이 약 1억 1,700만 개, GPT-2가 15억 개의 매개변수를 가진 반면, GPT-3는 1,750억 개로 폭증했다. 여기서 그치지 않고, 2023년의 GPT-4는 비공식적으로 GPT-3보다 10배나 더 큰 1조 8,000억 개의 매개변수를 가진 것으로 추정된다. 이처럼 모델의 규모가 엄청나게 커지면서 ‘Large’라는 단어는 이제 ‘대규모’를 넘어 ‘초거대’로 번역되고 있으며, 이 매개변수의 증가는 곧 모델의 성능 향상과 직결된다. 더욱 심각한 문제는, 인공지능이 단 하나의 추론(inference)을 해내기 위해서도 이 1조 8,000억 개에 달하는 막대한 매개변수를 모두 연산에 사용해야 한다는 점이다.
AI의 막대한 전력 소모 문제는 이제 단순한 기술적 난제를 넘어, 데이터센터의 입지까지 바꾸고 있다. AI 연산에 필요한 막대한 전력을 감당하기 위해, 데이터센터가 아예 원자력 발전소 근처로 가는 사례까지 등장한 것이다. 실제로 아마존(AWS)은 100% 원자력 발전으로 가동되는 데이터센터를 인수하기도 했다.
I 전력 위기 대응을 위한 해결책 : 3D 집적
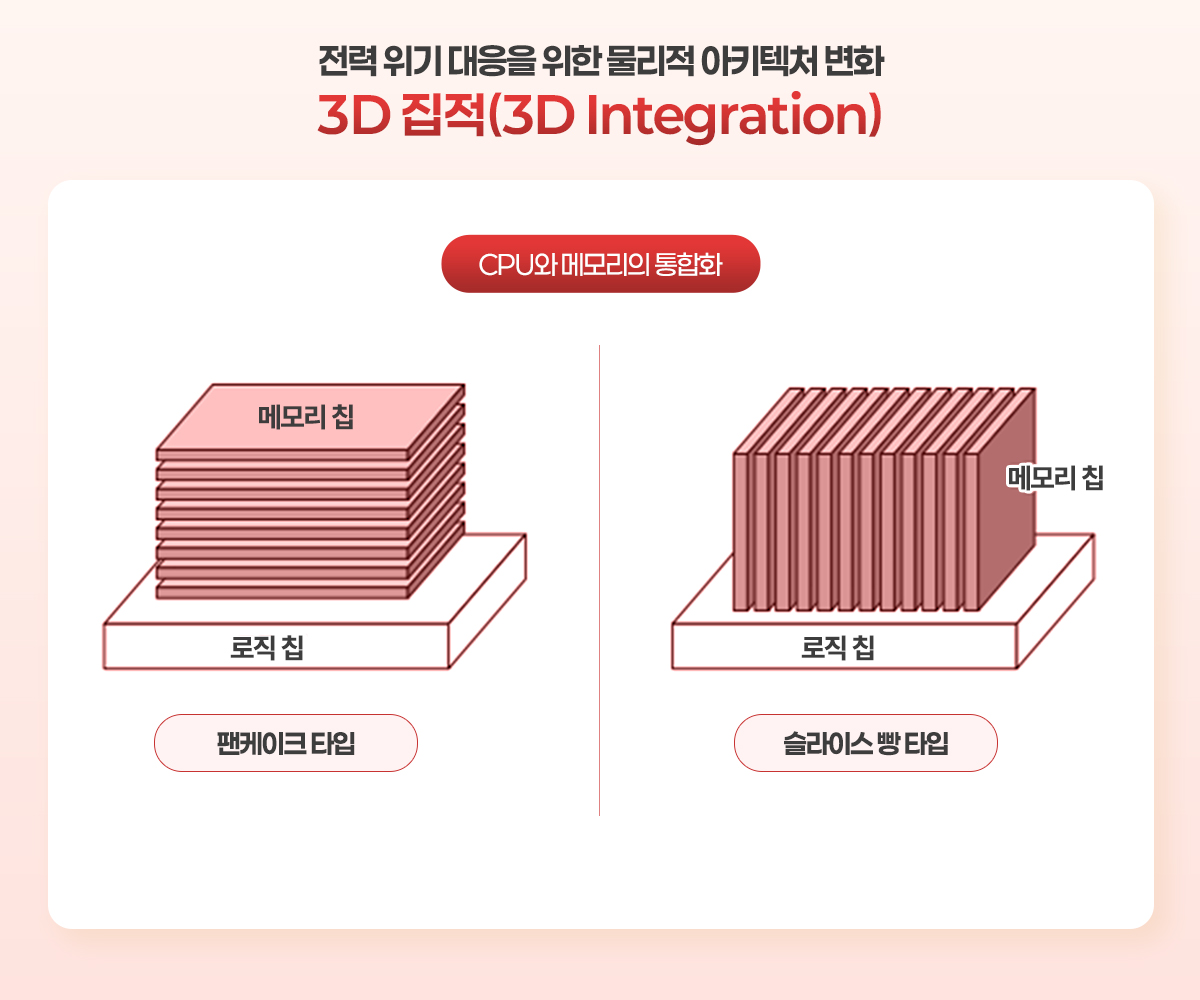
지금까지 살펴본 AI시대의 전력 위기는 폰 노이만 방식의 계산 구조가 가진 한계에서 비롯된다. 새로운 계산 패러다임이 등장하기 전까지, 이 문제를 완화하기 위한 해법은 일단 CPU와 메모리 사이의 거리를 최소화하는 것일 것이다. 그래서 나온 것이 ‘3D 집적(3D Integration)’ 이다. 이것은 (도표6)에서 볼 수 있듯 CPU와 같은 로직 칩 위에 메모리 칩을 쌓아 올리는 방식이다. 이렇게 칩을 3차원으로 집적하면 데이터가 이동하는 거리가 획기적으로 짧아져, 데이터 이동에 필요한 에너지를 차원이 다르게 줄일 수 있다. [도표 6] 좌측의 ‘팬케이크 타입’이 있으며, 아직 구현은 되지 않았지만, CPU 위에 수직 방향으로 메모리를 세우는 우측의 ‘슬라이스 빵 타입’ 방식도 있을 것이다.
이처럼 AI가 유발한 심각한 ‘전력 위기’라는 제약 조건은, 결국 CPU와 메모리가 명확히 분리되었던 기존의 아키텍처를 [도표6]에서 본 3D 집적처럼 서로 결합하는 ‘통합형(Integral)’ 아키텍처로 변화시키고 있다. 이는 비단 반도체 산업에만 국한된 현상이 아니다. 일반적으로 제품의 아키텍처는 이처럼 기존 방식으로는 도저히 해결할 수 없는 강력한 ‘제약 조건(constraint)’에 부딪혔을 때 근본적인 변화를 맞이하게 된다. 특히 그 제약 조건이 ‘성능’이나 ‘효율’의 극한을 요구할 경우, 아키텍처는 ‘모듈형(Modular)’의 유연성보다는 ‘통합형’ 구조로 회귀하며 시스템 전체의 ‘최적화’를 추구하는 경향이 강하다. 각 부품을 따로 개발해 조합하는 방식으로는 이룰 수 없는 극한의 효율을, 부품 간의 상호작용을 세밀하게 조율하는 통합 설계를 통해서만 달성할 수 있기 때문이다.
I 근본적 패러다임의 전환
: 분리형에서 다시 통합형으로
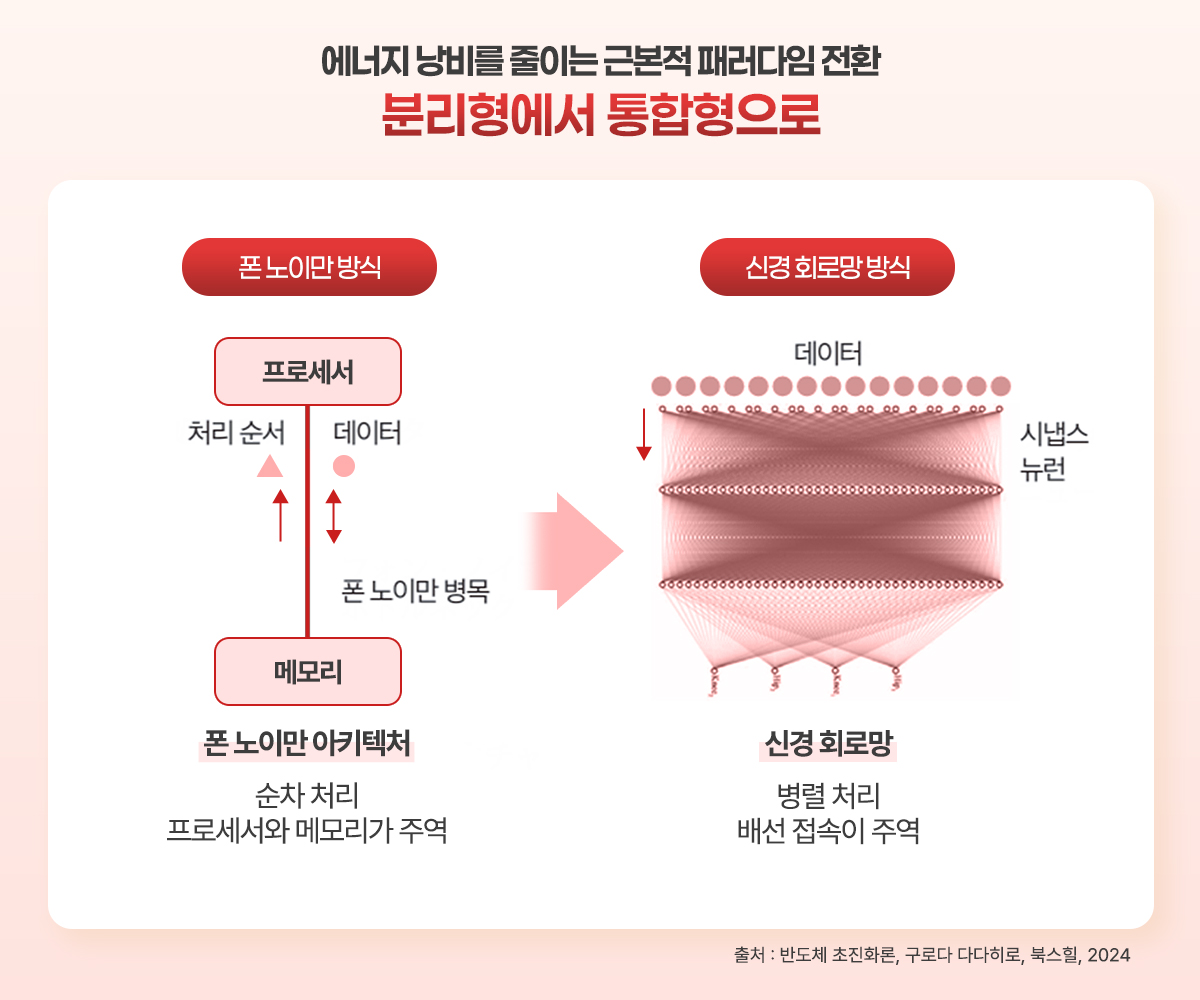
3D 집적을 통해 CPU와 메모리 간의 거리를 줄이려는 아키텍처 변화가 일어났지만, 어쩌면 이보다 더욱 근본적인 방식의 전환이 일어날 수도 있다. [도표 7]은 바로 ‘폰 노이만 방식’에서 ‘신경 회로망 방식’으로의 패러다임 전환을 보여준다. 좌측의 ‘폰 노이만 아키텍처’는 “프로세서와 메모리가 주역”이 되어 “순차 처리”를 하는 구조로, 에너지 낭비의 근본 원인이 된다. 반면, 우측의 ‘신경 회로망’은 “배선 접속이 주역”이 되어 데이터를 한꺼번에 “병렬 처리”한다. 이는 초창기 컴퓨터의 ‘배선 논리(wired logic) 방식’과 닮아 있다. 결국 AI의 등장은 반도체 아키텍처를 단순히 3D로 쌓는 차원을 넘어, 계산의 기본 원리 자체를 폰 노이만 이전으로 회귀시키며 근본적인 혁신을 촉진하고 있다.

[LX세미콘 소식 바로가기]
LX세미콘 공식 뉴스룸
LX세미콘 공식 블로그
LX세미콘 공식 유튜브
LX세미콘 공식 페이스북
LX세미콘 공식 인스타그램


